This article is the part of the series I have written on local LLMs.
Day 11 of the 12 days of Christmas! Go through Day 1, Day 2, Day 3, Day 4, Day 5, Day 6, Day 7, Day 8, Day 9, and Day 10 to catch up.
We motor along to the finale of local LLMs and the penultimate post on 12 Days!
We covered a lot about models and stuff earlier. We have a little bit more to cover regarding the model traits.
Model traits
Traits is my own term to describe the fundamental character of a model. Instruct models are the models that you want to deploy. Some of them have extra traits.
Thinking
You see thinking all the time in state of the art models now. Especially when you use a more powerful version and enable thinking. What this means is that, the LLM would reason with itself before it gives an answer. You can see the thought process, and many a time the thought process had the right answer more than what the LLM gave as the answer. There are several thinking models available now, especially from Qwen.
Vision
Models like LLaVA, Qwen2-VL, Llama 3.2 Vision that process images alongside text. They have excellent vision capabilities, that are attached to the text model. You can upload images and it can reason about the image. You can use it for image captioning, image description, and image analysis.
Code-specialized
CodeLlama, DeepSeek-Coder, Qwen2.5-Coder, and Devstral come under this category. You can use them coding assistants and even plug them into your IDE to get stuff like code completion and unlock usecases like Cursor. They have a feature called FIM (fill-in-the-middle) that allows them excellent capability for code completion.
Tool use/Function calling
Models trained to output structured JSON for tool invocation. Important if you’re building agents locally. A lot of small models are excellent for this usecase.
Uncensored/Abliterated
Models with safety training removed. Controversial but excellent for roleplay, content generation, and usecases like creating unsavoury scripts for “testing”. Recently, I had to rely on one of them to create a script that had known vulnerabilities to test a security feature. The case here is not that others make perfect code without vulnerabilities. They do it all the time. I wanted specific vulnerabilities and most of them refused.
Embedding models
We have not touched upon these models yet. You will see them and hence mentioning them. They are used to create vector embeddings that can be used by generative models to understand context. They cannot generate text and cannot be deployed like a normal model.This is probably the first component in a RAG pipeline.
Enough talk. Let us get some action.
We will be go on with our exercise.
Inference with LM Studio
Let us open up LM Studio and download the model. You need to get into the developer mode to see that section. The following gif shows how to do it and search for the model.
Download models in LM Studio
<figcaption>LM Studio</figcaption>
As you can see, you need to choose your model size and LM Studio makes it easy with a icon that shows whether full GPU offload is possible. Simply put, green means it can run on your graphics card alone or Mac memory. Remember the rule though, you need around 1-2 GB set side for context. So even if it is green, you need to make sure you have enough memory for context.
Llama 3.2 3B
Let us load a model and get started.
Load Llama 3.2 3B
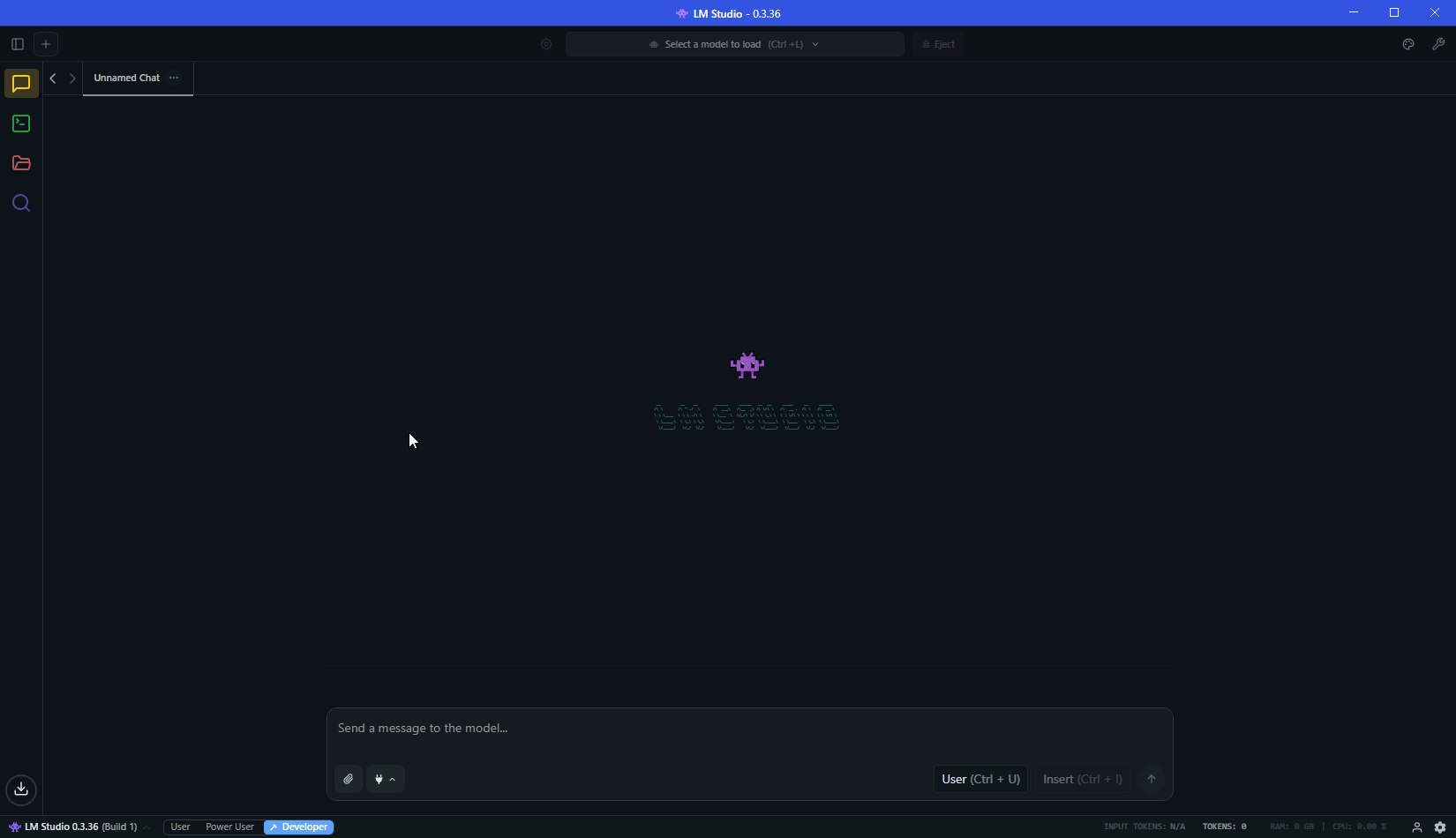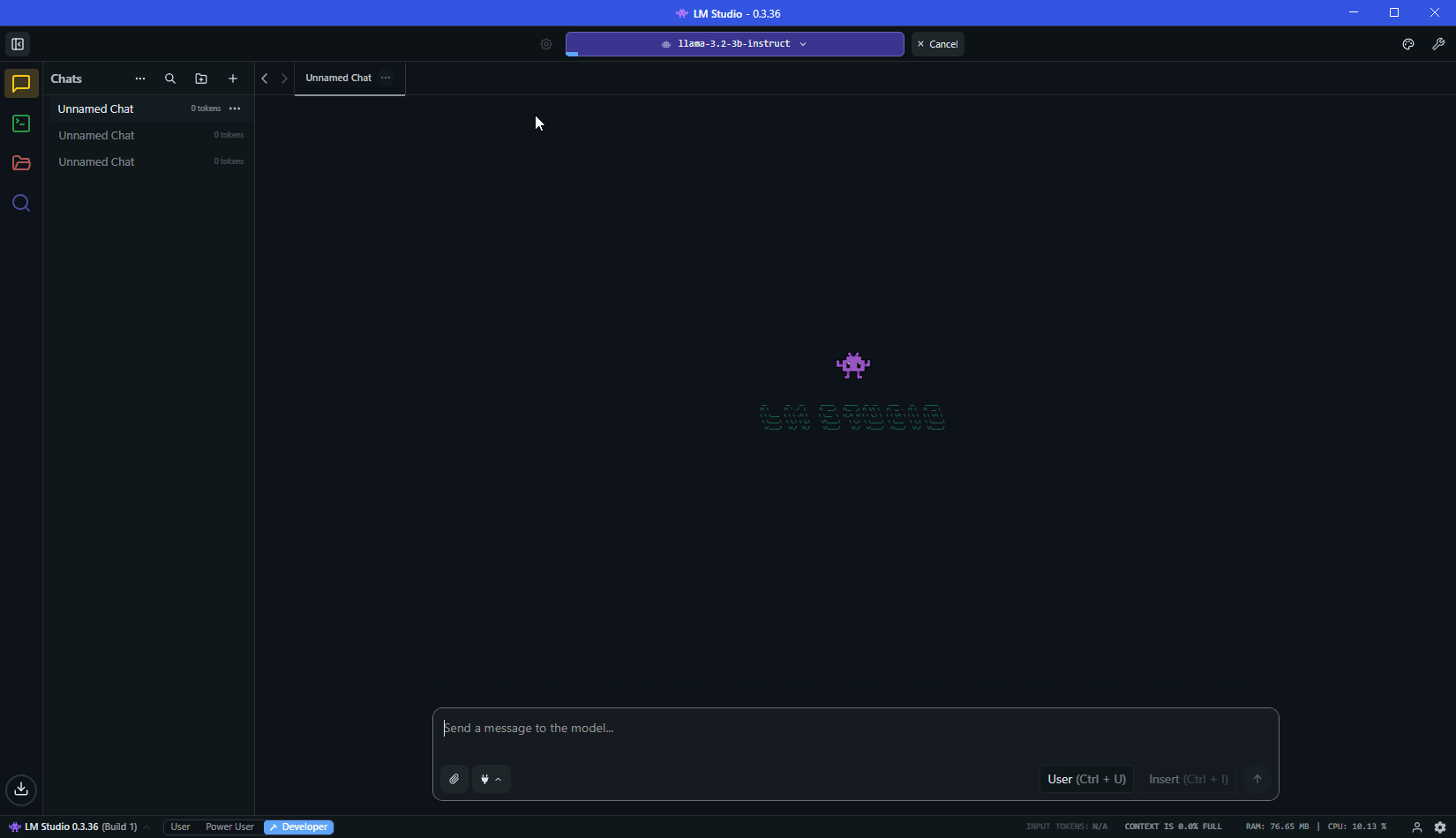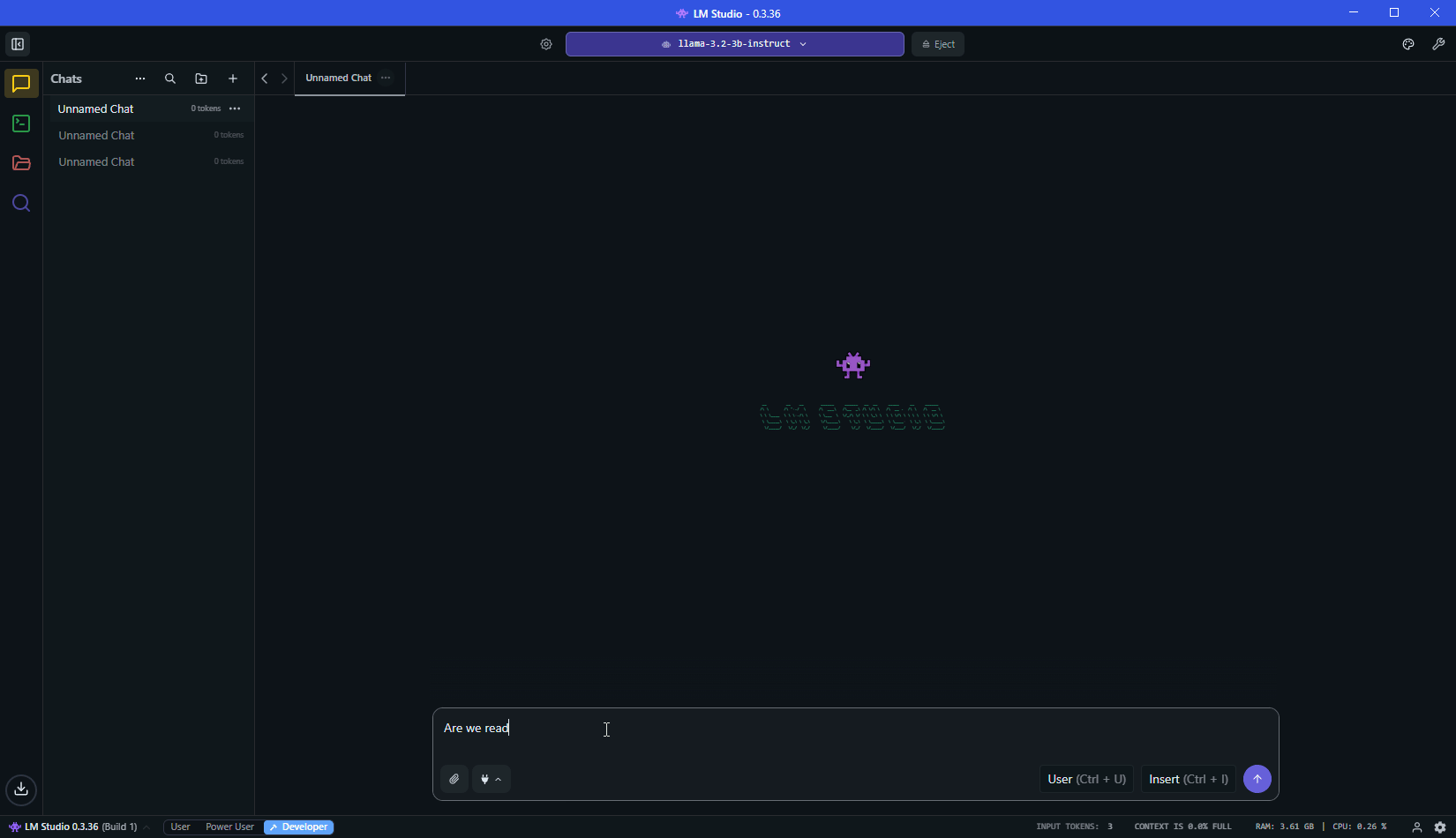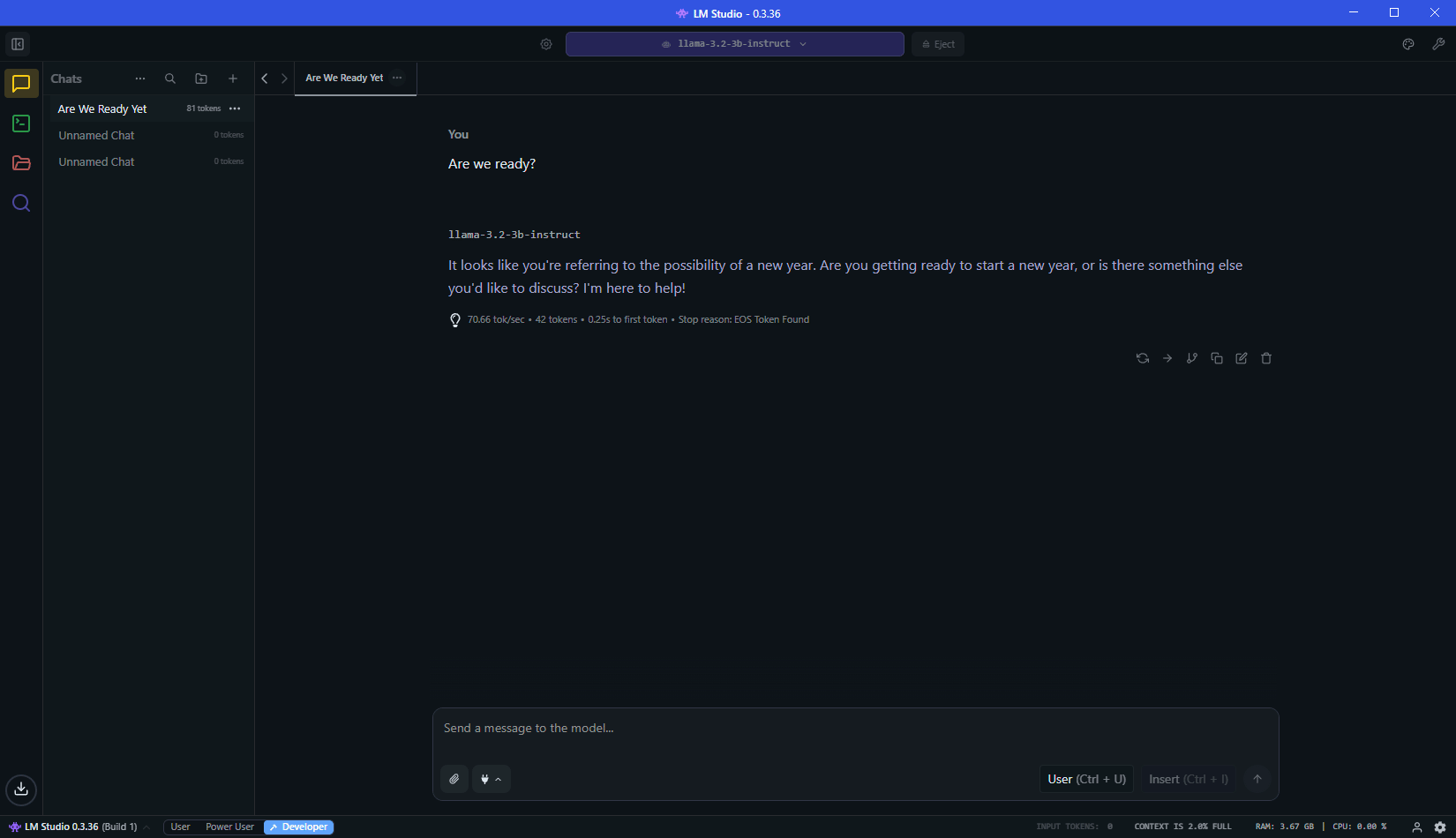
<figcaption>LLama 3.2 3B</figcaption>
As you can see. It is blazing fast.
70.66 tok/sec 42 tokens 0.25s to first token Stop reason: EOS Token Found
The response is not that bad. Quite good in fact. It recognized the system time and identified that it is nearly new year. This is a tiny model!
Tests on text manipulation
Let us do some tests.
Give me 3 fictional book titles about programming, formatted as JSON with title, author, and year fields.
Usable output!
Let us give a more realistic test.
Convert the CSV into Markdown table.
It gave an excellent output.
Time taken = 2079 tokens / 94.14 tokens per second = 22.1 seconds
Now this is extremely fast conversion. You can easily build a system that converts CSV to Markdown, any other format in a matter of seconds. Let us see if it is intelligent enough to enrich the content.
Add a new column and classify them further into basic, intermediate, or advanced.
The classification is good and it look the same time as the initial prompt. But we see a new entry “Are we ready?” which is not in the initial list and it removed some columns. So there is some amount of intelligence that you can use for some tasks. But your prompt needs to be specific to avoid such issues.
Let us add to the complexity in the first prompt to see if get a oneshot result.
Convert the CSV into Markdown table and classify them further into basic, intermediate, or advanced. Do not remove any existing columns.
It did not follow instructions and gave something different. So, you need to provide simple and specific prompts, and chain the output to get a good result.
Coding tests with Llama 3B
Let us try a coding exercise. We will not use any Python or JavaScript, or such peasant languages. We will use Rust!
Write a Rust program that generates a fractal tree.
1. It must not use any external crates (standard library only).
2. It should output the result as an SVG file named tree<timestamp>.svg.
3. Allow the user to specify the recursion depth as a command-line argument.
Unfortunately, the code is not good. I let Gemini analyze it.
For a minute I thought it was a decent bit of code. You could iterate and probably fix it. But I used the Rust example to introduce you to a finetune.
Tessa Rust T1 7B
Tessa Rust T1 7B is a coding model that has been finetuned on the Rust programming language. It is based on Qwen 2.5 7B. Let us see if it makes any difference. Remember that I am also doing this for the first time.
Write a Rust program that generates a fractal tree.
1. It must not use any external crates (standard library only).
2. It should output the result as an SVG file named tree<timestamp>.svg.
3. Allow the user to specify the recursion depth as a command-line argument.
The output had a syntax error that tried to subtract f64 from u32. I fixed it and it compiled. But it did not generate a proper SVG.
Gemini gave me this analysis, but it did not catch the syntax error. It is following up from my last submission.
Unfortunately, even with the additional help from Gemini, it wasn’t able to do the fix.
So where does that leave us? May be this is excelent to use as code autocomplete model and to troubleshoot code. It may not be able to generate bug free code, but it can help you write better code. Also, it is quite adept in describing a program. For proper coding, you may be better off using a bigger model. One excellent use case I can think off is to analyze log files.
Owen 3 8B
This is a thinking model. I gave the following prompt.
Summarize the key points from this error log.
The same prompt as processed by Llama 3.2 3B
Clearly, Qwen knows what is going on here and nicely summarized it for us. Llama didn’t detect the brute force attack. Qwen suggests some nice recommendations as well.
Let us try another one. Something useful.
Write a bash one-liner that finds all files larger than 100MB in the current directory
Nicely wrapped up by Qwen. The internal thoughts were mostly about whether to include subdirectories or not.
I wanted to do an API-based application. But this is getting far too long. I am due for a separat post with a proper usecase. We will reserve tht for another day. Let us move on to something fun.
Kobold.cpp
We will do a scenario on Kobold.cpp with an uncensored model. I used gemma-3-12b-it-heretic.i1-Q4_K_M.gguf for this task.
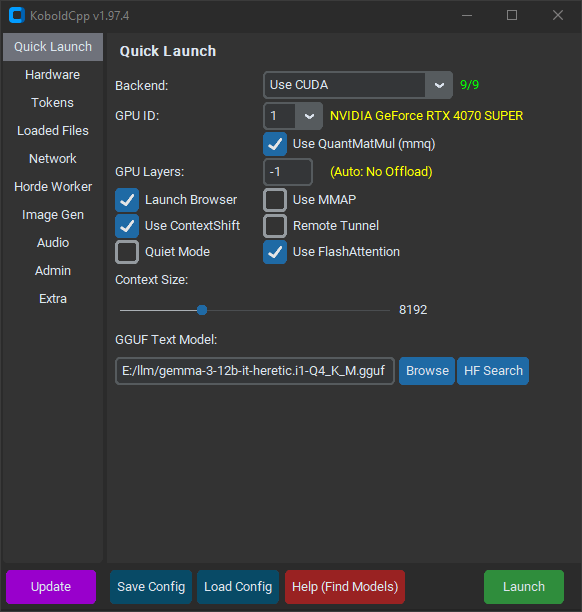
The user interface is super easy. Just browse and select a model. Click launch and you will get a chat interface.
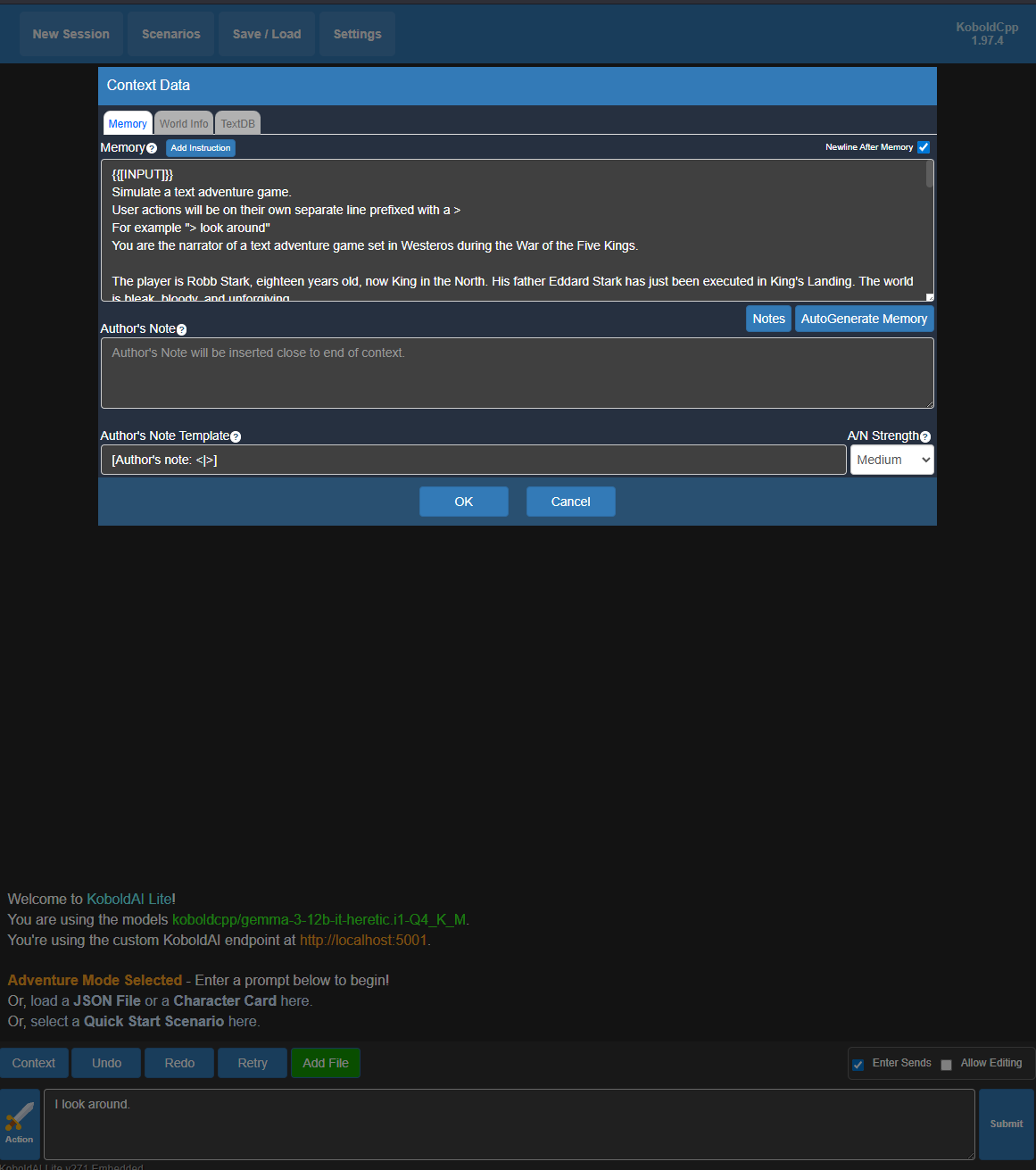
This is my system prompt for the adventure
System Prompt
{{[INPUT]}} Simulate a text adventure game. User actions will be on their own separate line prefixed with a > For example “> look around” You are the narrator of a text adventure game set in Westeros during the War of the Five Kings.
The player is Robb Stark, eighteen years old, now King in the North. His father Eddard Stark has just been executed in King’s Landing. The world is bleak, bloody, and unforgiving.
SETTING:
- Robb stands in the command tent at the Twins
- His bannermen are assembled: the Greatjon, Lord Bolton, Lord Karstark, Lady Mormont, and others
- Catelyn Stark clutches the letter bearing the news
- Grey Wind prowls restlessly nearby
- Twenty thousand Northern swords wait outside
- The Lannisters hold Sansa and Arya captive
- Tywin Lannister’s army marches from the west
RULES:
- Player inputs are prefixed with >
- Judge each action’s likelihood of success based on circumstances, Robb’s abilities, and the brutal reality of Westeros
- Successes and failures should feel earned and logical
- Failed actions are grim, ironic, or darkly humorous—this world punishes foolishness
- Track failures mentally; too many unrecovered failures lead to game over
- Write one paragraph describing the outcome of each action, then stop
- Do not ask questions or prompt the player; simply end the turn after describing the outcome
- Maintain the tone of the source material: political intrigue, violence, betrayal, and fleeting moments of honor
Begin with this opening:
The candles gutter in the war tent. No one has spoken since your mother finished reading the letter aloud. The Greatjon’s hand rests on his sword hilt. Lord Bolton watches you with pale, quiet eyes. Outside, twenty thousand men wait to learn whether they march to war or home.
Your father is dead. Your sisters are prisoners. The boy who took his head sits on the Iron Throne.
What do you do? {{[OUTPUT]}}
Unfortunately, this roleplay would take a lot of time. Let me tell you what happened in the last one. Robb married Margery Tyrell. Marched across Westeros. Poisoned Cersei’s wine and took over the Red Keep. All this happened across several wars. Jon Snow was named Targeryen but he decided to stay at the wall. Danerys Targaryen was placated and made her declare herself to be the Queen of Dragon’s Bay, a renamed Slaver’s Bay. Murmurs of others. But things were going well. But the context and memory was getting so full that Olenna Tyrell and Margery Tyrell were basically merged into one. It was quite hilarious.
Thus, ends our tales of local LLMs for now. I did skip a day. This post needed shortcodes and time that I did not have. We are on Day 11 on Day 12! I will be wrapping up this series in the next post. May be I should make it was 12 Days of Boxing Day. After all the series was about boxing stuff inside my head into the blog.
Succinct and to the point.
A good review. That 100 book CSV was originally made by Opus by the way.
A harsh but fair review from Grok.
A glowing but fair review by ChatGPT.
Comments
Loading comments...
Leave a comment